Let’s face it – managing data can be a headache. But what if your database could think like you do? That’s where Claris FileMaker’s latest release comes in, bringing some seriously cool AI tricks to the table.
Imagine this: you’re looking for that one elusive piece of information buried in your database. Instead of sifting through countless records, you simply ask FileMaker to find it – and it actually understands what you mean, not just the exact words you use. Or picture spotting trends in your data without spending hours crunching numbers. With FileMaker’s new AI features, these aren’t just pipe dreams – they’re a few script steps away from reality.
We’re not just talking about a smarter database here. This is about transforming FileMaker into your personal data wizard, ready to make your work life easier, faster, and yeah, maybe even a bit more fun. So, ready to see how FileMaker and AI can take your data management game to the next level? Let’s dive in!
This is about transforming FileMaker into your personal data wizard, ready to make your work life easier, faster, and yeah, maybe even a bit more fun.
Xandon Frogget

Enhancing Data Analysis with AI
Claris FileMaker’s latest release brings AI capabilities to your fingertips, transforming how you manage, search, and analyze your data. The real power of the new script steps lies in creating and managing embeddings. But what exactly are embeddings?
Understanding Embeddings in AI
Embeddings are like digital maps of words or ideas. Imagine a vast space (called a high-dimensional vector space) where each word is a point. Words with similar meanings are placed closer together in this space, like constellations. For example, ‘dog’ and ‘puppy’ would be near each other, but far from words like ‘car’. Computers represent these word positions using lists of numbers, called vectors. This number-based map helps computers understand the relationships between words, capturing their semantic meaning and making it easier for machines to grasp the context behind text.
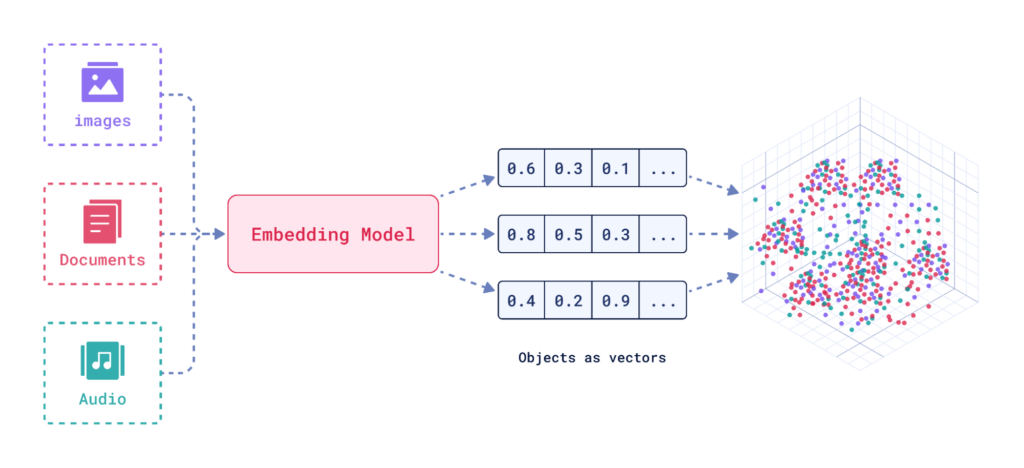
How are Embeddings Useful?
1. Semantic Understanding: Embeddings capture the meaning and context of data, allowing for more nuanced analysis than simple keyword matching.
2. Efficient Computation: Vector representations allow for fast and efficient calculations of similarity between different pieces of data.
3. Dimensionality Reduction: Complex data is compressed into a more manageable form while preserving important features.
4. Machine Learning Input: Embeddings serve as excellent input features for various machine learning models.
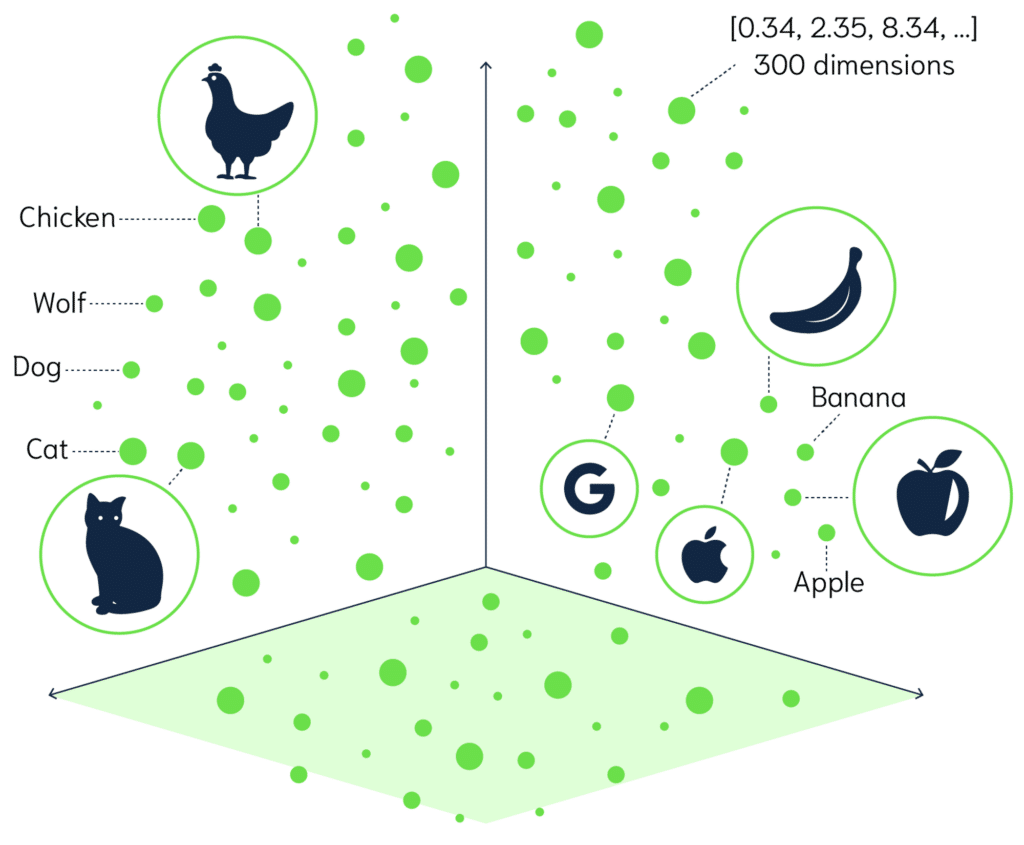
When to Use Embeddings?
Embeddings are particularly useful in scenarios involving:
1. Natural Language Processing: For tasks like semantic search, text classification, or sentiment analysis.
2. Recommendation Systems: To find similar items based on their characteristics.
3. Information Retrieval: For more accurate and context-aware document searches.
4. Data Visualization: To represent complex data in lower-dimensional spaces for analysis.
5. Anomaly Detection: To identify outliers or unusual patterns in data.
Benefits of Using Embeddings
By leveraging embeddings in FileMaker, developers can create more intelligent, context-aware applications that provide enhanced search capabilities, better recommendations, and deeper insights into their data.
1. Improved Search Accuracy: Find semantically related content, not just exact matches.
2. Enhanced User Experience: Provide more relevant recommendations and search results.
3. Deeper Data Insights: Uncover hidden relationships and patterns in your data.
4. Scalability: Efficiently process and analyze large volumes of unstructured data.
5. Cross-lingual Applications: Some embedding models can capture meaning across different languages.
6. Versatility: Applicable to various data types and numerous AI/ML tasks.
New AI Capabilities in FileMaker
Enhancing Data Management with AI

To harness the power of AI and embeddings, Claris FileMaker has introduced new script steps and functions:
- Script Steps
- Functions
In the following sections, we’ll take a closer look at each of these new script steps and functions, followed by some practical tips to help you make the most of these powerful new AI features in FileMaker.
Detailed Explanation of Each New FileMaker Script Step
Configure AI Account
Purpose: Sets up an AI account by specifying a model provider and an API key, making it available for other AI script steps and functions. This step is as a first step before being able to interact with any AI model.
Options:
- Account Name: A unique name for the AI account, used for referencing in other steps.
- Model Provider: The AI model provider. For custom providers, specify the endpoint URL.
- Endpoint: The URL for the API endpoint if using a custom model provider.
- API Key: The key that authorizes the use of the model provider’s service.
Example:
Configure AI Account [ Account Name: "my_account"; Model Provider: OpenAI; API Key: "sk-RZCtpWT..." ]Insert Embedding
Purpose: Converts specified input text into embedding vectors and inserts these vectors into a container, field, or variable.
Options:
- Account Name: The AI account for this script step.
- Embedding Model: The model used to generate embedding vectors.
- Input: The text to be converted into embedding vectors.
- Target: The field or variable where the embedding vectors will be inserted.
Example:
Configure AI Account [ Account Name: "my-account"; Model Provider: OpenAI; API key: "sk-RZCtpWT..." ]
Go to Layout [ "Meeting Details" (Meetings); Animation: None ]
Insert Embedding [ Account Name: "my-account"; Embedding Model: "text-embedding-3-small"; Input: Meetings::Note; Target: Meetings::Note_Embedding ]Insert Embedding in Found Set
Purpose: Inserts embedding vectors into a specified container field for every record in the found set based on the content of another specified field.
Options:
- Account Name: The AI account for this script step.
- Embedding Model: The model used to generate embedding vectors.
- Source Field: The text field whose values will be converted into embedding vectors.
- Target Field: The field where the embedding vectors will be inserted.
- Replace target contents: Whether to replace existing data in the target field.
Example:
Configure AI Account [ Account Name: "my-account"; Model Provider: OpenAI; API key: "sk-RZCtpWT..." ]
Go to Layout [ "Meeting Details" (Meetings); Animation: None ]
Show All Records
Insert Embedding in Found Set [ Account Name: "my-account"; Embedding Model: "text-embedding-3-small"; Source Field: Meetings::Note; Target Field: Meetings::Note_Embedding; Replace target contents ]Perform Semantic Find
Purpose: Performs a semantic search in a specified field, constraining the record set based on search text or embedding vectors.
Options:

- Query by: Whether the query is natural language text or embedding vector data.
- Record set: Whether to search all records or the current found set.
- Target field: The field to search in, which must contain embedding vectors.
- Return count: The number of semantically similar records to return.
- Cosine similarity condition: How the cosine similarity of the data is compared to the cosine similarity value.
- Cosine similarity value: The threshold for determining similarity.
Example:
Configure AI Account [ Account Name: "my-account"; Model Provider: OpenAI; API key: "sk-RZCtpWT..." ]
Go to Layout [ "Meeting Details" (Meetings); Animation: None ]
Perform Semantic Find [ Query by: Natural language; Account Name: "my-account"; Embedding Model: "text-embedding-3-small"; Text: "Recruitment, job definition, training plan"; Record set: All records; Target field: Meetings::Note_Embedding; Return count: 10; Cosine similarity condition: greater than; Cosine similarity value: .4 ]Set AI Call Logging
Purpose: Controls whether details of AI calls are saved to a log file. This log file is saved in the current user’s Documents folder.
Options:
- On/Off: Starts or stops logging AI calls.
- Filename: The name of the log file. Default is “LLMDebug.log”.
- Verbose: Logs additional information such as embedding vectors and token usage.
Example:
Set AI Call Logging [ On; Filename: "ai-calls.log"; Verbose ]
Configure AI Account [ Account Name: "my-account"; Model Provider: OpenAI; API key: "sk-RZCtpWT..." ]
Go to Layout [ "Meeting Details" (Meetings); Animation: None ]
Insert Embedding [ Account Name: "my-account"; Embedding Model: "text-embedding-3-small"; Input: Meetings::Note; Target: Meetings::Note_Embedding_Text ]Overview of Each of the New Functions
FileMaker Pro 21 introduced several new AI-related functions to complement its AI script steps. These functions facilitate working with embedding vectors and provide utilities for AI-related tasks. Here’s a brief overview of each function:
CosineSimilarity(v1; v2)
Purpose: Calculates the similarity between two embedding vectors.
Input: Two embedding vectors (as text or container fields).
Output: A number between -1 (opposite) and 1 (similar).
Use case: Comparing the semantic similarity of two pieces of text.
GetEmbedding(account; model; text)
Purpose: Generates an embedding vector for given text.
Input: AI account name, model name, and input text.
Output: Embedding vector as container data.
Use case: Creating embedding vectors for semantic search or text comparison.
GetEmbeddingAsFile(text; fileNameWithExtension)
Purpose: Converts a text-format embedding vector to binary container data.
Input: Embedding vector as JSON array text, optional filename.
Output: Embedding vector as container data.
Use case: Preparing embedding vectors for storage or export.
GetEmbeddingAsText(data)
Purpose: Converts a binary embedding vector to text format.
Input: Embedding vector as container data.
Output: Embedding vector as JSON array text.
Use case: Converting stored embedding vectors for display or processing.
GetTableDDL(tableOccurrences)
Purpose: Retrieves table information in Data Definition Language (DDL) format.
Input: JSON array of table occurrences.
Output: DDL representation of specified tables.
Use case: Generating database schema information for AI models.
GetTokenCount(text)
Purpose: Estimates the number of tokens in a given text.
Input: Any text string.
Output: Estimated token count.
Use case: Checking if text length is suitable for AI model processing.
Get(LastStepTokensUsed)
Purpose: Retrieves the token count used in the last AI script step.
Input: None (system function).
Output: Number of tokens used.
Use case: Monitoring token usage for API quota management.
Tips for Implementing 2024’s New AI FileMaker Script Steps
By implementing these tips, you can make the most of FileMaker 2024’s new AI capabilities while optimizing performance and maintaining data integrity. We’ve assembled these suggestions from our own research and experience, as well as from information in these excellent articles:
- FileMaker Pro – Release notes – Claris
- “A Deep Dive into FileMaker 2024’s new Semantic Search Functionality” by Ian Jempson
- “Using an On-prem LLM for AI Semantic Search in FileMaker 21” by Wim Decorte

Optimizing Embedding Storage and Performance
1. Use container fields for embeddings: Store embeddings in container fields rather than text fields for better performance. This prevents accidental indexing and allows for external storage to prevent file bloating.
2. Separate embeddings table: Create a separate table for embeddings instead of storing them with the main record. This allows for easier relationship management and using different embedding models on the same record.
3. Store embedding model information: Keep track of which model was used to generate each embedding. This helps when working with multiple models or optimizing your setup.
Enhancing Embedding and Search Speed
4. Utilize ‘Insert Embeddings in Found Set’: This method is faster than looping through records individually, as it performs calculations on the entire found set at once.
5. Leverage Perform Script on Server (PSOS): Using PSOS for embedding operations can provide a substantial speed boost.
6. Optimize batch size: Experiment with the number of records sent per call to the model server (up to 500) to find the optimal balance for your setup.
Choosing and Using Models Effectively
7. Experiment with different models: Consider accuracy, speed, and cost when choosing models. FileMaker 2024 supports popular OpenAI models like ‘text-embedding-ada-002’ for general use, and ‘text-embedding-3-small’ or ‘text-embedding-3-large’ for more recent capabilities, as well as open-source options such as ‘all-MiniLM-L12-v2’. Refer to the FileMaker documentation for a list of compatible models and their characteristics.
8. Mind input length limitations: Be aware of your chosen model’s maximum input length. OpenAI models like ‘text-embedding-ada-002’ have a limit of 8191 tokens (roughly 4000-5000 English words). Open-source models typically range from 256-512 tokens (about 190-380 English words). For example, the ‘all-MiniLM-L12-v2’ model has a limit of 256-512 tokens. Check the model’s documentation for specific limits to ensure optimal performance. Note that open-source sentence transformers truncate inputs if they exceed their range.
9. Use semantic search for unstructured data: Semantic searches work best with free-form text (like movie plots or book reviews) rather than structured data (such as spreadsheets or JSON), as they can better capture the context and nuances in loosely formatted content.
Implementing Advanced Features
10. Utilize the Cosine Similarity function: This can help display similarity scores to users and evaluate which embedding model might be best for your use case, but be mindful that frequent calculations may impact performance for large datasets.
11. Implement cosine similarity calculations: For more precise control over search results, use the CosineSimilarity function in an unstored calculation field to sort results by relevance. However, consider pre-calculating and storing similarity scores for frequently compared items to optimize performance.
12. Use GetTokenCount for cost estimation: This function can help estimate embedding costs before running the process, helping to manage budgets effectively.
Best Practices and Cautions
13. Be cautious with verbose logging: When enabled, verbose logging records all requests and responses in plain text, which could include sensitive data.
14. Pre-filter before semantic search: For large databases, pre-filtering the dataset before performing a semantic search can significantly improve performance.
We’re Ready to Assist in Implementing AI Capabilities Into Your FileMaker Solution
We hope you’ve enjoyed this exploration of the new AI FileMaker script steps that are available. We’re putting together a second article detailing some practical applications and use cases. If you’re a developer, comment below to let us know what ways you’ve found to begin incorporating this new technology into your solutions.
If you’re a client, or are looking for a development partner, are you ready to make your work life easier, faster, and even a bit more fun, as we suggested at the start of this post? Contact us to get on our calendar. We’ll start with a complimentary consultation and then will be delighted to map out a course of action to ramp up your FileMaker solution capabilities.
About the Author
Xandon Frogget, Senior Application Developer, brings sixteen years of corporate experience at OfficeMax, where he designed FileMaker solutions for their large-scale printing and production facilities. He has a knack for working in corporate environments, understanding needs from the user’s point of view, and communicating and training staff for seamless transitions.